從單機到億級流量 大型網(wǎng)站系統(tǒng)架構(gòu)的演進之路
在互聯(lián)網(wǎng)蓬勃發(fā)展的今天,一個成功的網(wǎng)站應(yīng)用可能從寥寥數(shù)人的初創(chuàng)項目,迅速成長為服務(wù)億萬用戶的技術(shù)巨擘。其背后的系統(tǒng)架構(gòu),也必須經(jīng)歷一場持續(xù)演進、不斷蛻變的旅程。這個過程不僅是技術(shù)的升級,更是對可擴展性、高可用性、高性能與可維護性核心訴求的深刻回應(yīng)。本文將系統(tǒng)梳理從單機起步,直至支撐億級流量的超大型分布式系統(tǒng)的典型架構(gòu)演進路徑。
第一階段:單機架構(gòu)——一切的起點
幾乎所有大型網(wǎng)站都始于一個簡單的想法和一個更簡單的實現(xiàn)。在初期,為了快速驗證產(chǎn)品(MVP)和節(jié)省成本,整個應(yīng)用通常被部署在一臺物理服務(wù)器或虛擬機上。應(yīng)用程序、數(shù)據(jù)庫、文件存儲等所有組件都集中于此。
- 技術(shù)棧:LAMP(Linux, Apache, MySQL, PHP)或類似的簡單組合是典型代表。
- 特點:結(jié)構(gòu)簡單,開發(fā)部署快捷,成本極低。
- 挑戰(zhàn):存在嚴(yán)重的單點故障風(fēng)險;性能瓶頸明顯,隨著用戶量增長,CPU、內(nèi)存、I/O很快會成為瓶頸;擴展性幾乎為零,無法通過增加機器來提升能力。
第二階段:應(yīng)用與數(shù)據(jù)分離——首次解耦
當(dāng)單臺服務(wù)器的處理能力達到上限,最直接有效的第一步是將應(yīng)用服務(wù)器和數(shù)據(jù)庫服務(wù)器分離,部署到不同的機器上。
- 演進:一臺服務(wù)器專用于運行業(yè)務(wù)應(yīng)用程序,另一臺(或集群)專門負(fù)責(zé)數(shù)據(jù)存儲(如MySQL)。兩者通過內(nèi)網(wǎng)連接。
- 價值:實現(xiàn)了初步的解耦,便于針對應(yīng)用服務(wù)器和數(shù)據(jù)庫服務(wù)器進行獨立的優(yōu)化和擴展。例如,可以為應(yīng)用服務(wù)器配置更高的CPU,為數(shù)據(jù)庫服務(wù)器配置更大的內(nèi)存和更快的磁盤。
第三階段:應(yīng)用服務(wù)器集群與負(fù)載均衡——橫向擴展的開端
應(yīng)用服務(wù)器分離后,其自身很快會成為新的瓶頸。引入負(fù)載均衡器(如Nginx, HAProxy)和應(yīng)用服務(wù)器集群是應(yīng)對之道。
- 架構(gòu):用戶請求首先到達負(fù)載均衡器,由它按照一定策略(如輪詢、最小連接數(shù))分發(fā)到后方多臺應(yīng)用服務(wù)器中的一臺。
- 關(guān)鍵點:
- 會話(Session)管理:由于用戶請求可能被分發(fā)到不同的服務(wù)器,需要解決Session共享問題,方案包括Session復(fù)制、Session綁定(粘滯會話)或?qū)挃?shù)據(jù)集中存儲到外部緩存(如Redis)。
- 高可用:負(fù)載均衡器本身可能成為單點,需要通過主備或集群方式保障其高可用。
- 價值:通過水平擴展應(yīng)用服務(wù)器,系統(tǒng)處理并發(fā)請求的能力得到線性提升,也提高了應(yīng)用層的可用性。
第四階段:數(shù)據(jù)庫讀寫分離與分庫分表——突破數(shù)據(jù)層瓶頸
應(yīng)用層擴展后,壓力會迅速傳導(dǎo)至數(shù)據(jù)庫。單一的數(shù)據(jù)庫服務(wù)器會面臨巨大的讀寫壓力。
- 讀寫分離:引入主從復(fù)制,主庫負(fù)責(zé)寫操作,多個從庫負(fù)責(zé)讀操作。應(yīng)用程序通過數(shù)據(jù)庫中間件或框架配置,將讀寫請求路由到不同的數(shù)據(jù)庫實例。這極大地緩解了讀壓力。
- 分庫分表:當(dāng)單個數(shù)據(jù)庫實例的存儲容量或?qū)懶阅苓_到極限時,需要對數(shù)據(jù)進行水平拆分。
- 垂直分庫:按業(yè)務(wù)模塊將不同表拆分到不同的數(shù)據(jù)庫(如用戶庫、訂單庫)。
- 水平分表/分庫:將同一個表的數(shù)據(jù)按某種規(guī)則(如用戶ID哈希、時間范圍)分散到多個表或多個數(shù)據(jù)庫中。
- 挑戰(zhàn):引入了分布式事務(wù)、跨庫查詢、全局唯一ID生成等復(fù)雜問題。
第五階段:引入緩存與CDN——加速與減壓
大部分網(wǎng)站訪問遵循二八定律(80%的請求集中在20%的數(shù)據(jù)上)。利用緩存技術(shù)可以極大提升響應(yīng)速度并降低后端壓力。
- 本地緩存與分布式緩存:
- 首先在應(yīng)用服務(wù)器本地使用Guava Cache等,減少內(nèi)部計算開銷。
- 更重要的是引入Redis、Memcached等分布式緩存集群,存儲熱點數(shù)據(jù)(如用戶信息、熱門商品),避免頻繁訪問數(shù)據(jù)庫。
- CDN(內(nèi)容分發(fā)網(wǎng)絡(luò)):對于靜態(tài)資源(圖片、CSS、JS、視頻),將其推送到遍布全球的CDN節(jié)點。用戶訪問時,由最近的CDN節(jié)點提供服務(wù),極大降低網(wǎng)絡(luò)延遲,減輕源站帶寬壓力。
第六階段:業(yè)務(wù)拆分與微服務(wù)架構(gòu)——面向復(fù)雜性的進化
當(dāng)系統(tǒng)功能日益龐雜,單體應(yīng)用會變得臃腫不堪,開發(fā)、部署、維護都極其困難。通過業(yè)務(wù)拆分,將系統(tǒng)解耦為一組小型、自治的服務(wù)。
- 演進:從單一應(yīng)用按業(yè)務(wù)模塊拆分為多個獨立的服務(wù),如用戶服務(wù)、商品服務(wù)、訂單服務(wù)、支付服務(wù)等。
- 關(guān)鍵技術(shù):
- 服務(wù)治理:服務(wù)注冊與發(fā)現(xiàn)(如Nacos, Consul, Eureka),服務(wù)間通信(REST, gRPC),負(fù)載均衡,熔斷降級(如Hystrix, Sentinel)。
- 統(tǒng)一網(wǎng)關(guān):提供統(tǒng)一的API入口,處理路由、認(rèn)證、監(jiān)控、限流等橫切關(guān)注點。
- 配置中心與鏈路追蹤:實現(xiàn)配置的集中管理和服務(wù)調(diào)用鏈路的可視化排查。
- 價值:提升開發(fā)效率與系統(tǒng)可維護性,允許不同服務(wù)獨立部署和擴展,技術(shù)棧也可多樣化。但同時也帶來了分布式系統(tǒng)固有的復(fù)雜性,如網(wǎng)絡(luò)不可靠、數(shù)據(jù)一致性、運維監(jiān)控成本增加等。
第七階段:全面分布式與云原生——億級流量的基石
為了支撐億級甚至更高的并發(fā)流量和數(shù)據(jù)處理需求,架構(gòu)需要進化到全面分布式和云原生階段。
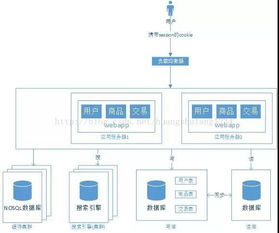
- 數(shù)據(jù)層深化:
- 多級緩存架構(gòu):客戶端緩存 -> CDN -> 反向代理緩存(Nginx) -> 分布式緩存 -> 數(shù)據(jù)庫,形成多級屏障。
- 異構(gòu)數(shù)據(jù)存儲:根據(jù)數(shù)據(jù)特性選用最合適的存儲,如關(guān)系型數(shù)據(jù)庫(MySQL/PostgreSQL)、NoSQL(MongoDB, Cassandra)、時序數(shù)據(jù)庫(InfluxDB)、搜索引擎(Elasticsearch)、對象存儲(OSS/S3)等。
- 消息隊列解耦與削峰:大規(guī)模使用Kafka、RocketMQ、Pulsar等消息隊列,實現(xiàn)系統(tǒng)間的異步解耦、流量削峰填谷和數(shù)據(jù)流處理。
- 彈性計算與容器化:采用Docker容器和Kubernetes編排系統(tǒng),實現(xiàn)服務(wù)的快速部署、彈性伸縮和故障自愈,資源利用效率最大化。
- 服務(wù)網(wǎng)格(Service Mesh):將服務(wù)通信、治理能力(如流量管理、安全、可觀測性)下沉到基礎(chǔ)設(shè)施層(如Istio),使業(yè)務(wù)代碼更專注于邏輯本身。
- 大數(shù)據(jù)與實時計算:構(gòu)建獨立的大數(shù)據(jù)平臺,使用Flink、Spark等處理海量日志和用戶行為數(shù)據(jù),進行實時分析與決策。
###
從單機到億級流量的架構(gòu)演進,是一個持續(xù)應(yīng)對壓力、解決瓶頸、擁抱復(fù)雜性的過程。其核心思想始終是:分解、抽象、解耦和冗余。沒有一種架構(gòu)可以一勞永逸,優(yōu)秀的架構(gòu)總是與業(yè)務(wù)共同成長,在不斷迭代中尋找成本、效率、性能和復(fù)雜度之間的最佳平衡點。對于架構(gòu)師和開發(fā)者而言,理解這一演進歷程的內(nèi)在邏輯,遠(yuǎn)比掌握某個具體技術(shù)更為重要,因為這能幫助我們在面對系統(tǒng)發(fā)展的不同階段時,做出最合適的技術(shù)決策。
如若轉(zhuǎn)載,請注明出處:http://www.pangrui.com.cn/product/56.html
更新時間:2026-04-11 13:59:47